 Recomiendo abrir la imágen en otra ventana, clickearla para que se agrande, y consultarla a medida que se lee el post. Vale la pena.
Recomiendo abrir la imágen en otra ventana, clickearla para que se agrande, y consultarla a medida que se lee el post. Vale la pena.
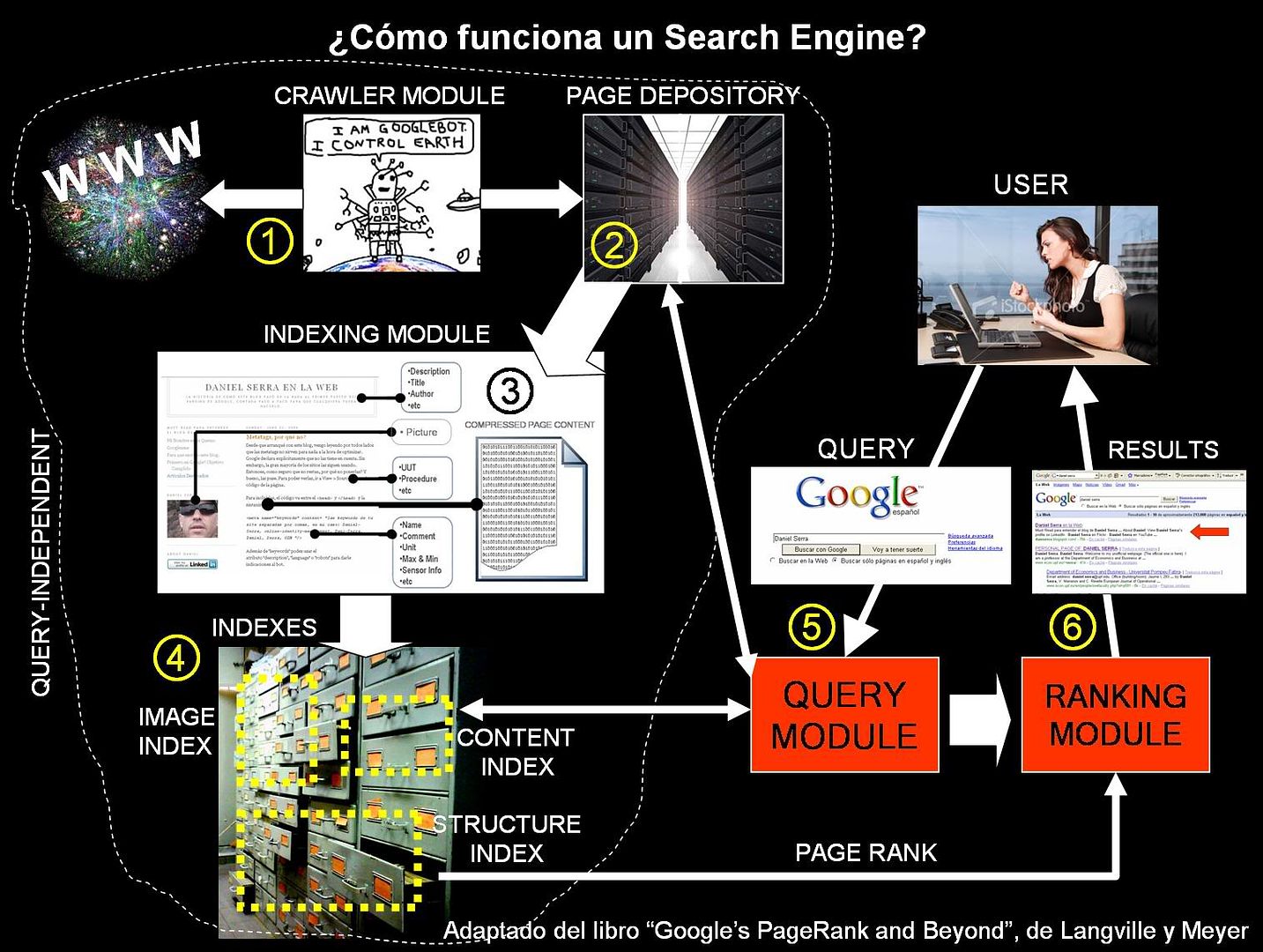
1) Todo empieza con un bot (también llamado crawler, o spider) que se ocupa de recolectar la información que está desparramada por los miles de servers que forman la world wide web. No hay en ningún lado una lista de los sitios web existentes en un determinado momento, las empresas que dan servicio de Search Engine (Google, Yahoo!, etc) deben auto-generarse esa lista. El bot no es ni más ni menos que un programita que visita páginas de internet de manera automática, las copia, las manda al “Page Depository”, luego visita cada uno de los links que tenía esa página y así sucesivamente. De esa manera, recorre la gran mayoría de las páginas de internet existentes y relevantes (Google tenía 8,1 billones a Noviembre del 2004), aunque son muchas las que se le escapan. Ahora, para mantener el “Page Depository” actualizado, las páginas que cambian en forma diaria también deben ser actualizadas diariamente. Para eso existe un bot especial llamado “fresh bot” que visita más frecuentemente los sitios que refrescan su contenido en forma permanente.
2) El “Page Repository” es el caché, o sea, el lugar donde se guarda la última actualización de una determinada página según la copió el bot. Toneladas de información acumulada en discos rígidos. Cuando se hace una búsqueda en Google, al final de cada resultado aparece un link que dice “En caché”. Ahí se puede ver la página que está guardada en el “Page Repository” correspondiente a la última vez que el bot pasó a visitarla. Por supuesto que la página real puede haber cambiado desde ese momento. Acá hay un ejemplo de una página del caché de este blog.
3) El “Indexing module” toma cada página nueva del “Page Repository” y extrae la información más importante, creando una versión comprimida que luego va a ser utilizada en los índices. Esa información incluye: título, descripción, anchor texts, texto en bold o en tamaño mayor, links hacia otras páginas, texto, etc.
4) Con la información extraída en el “Indexing module” se confeccionan los distintos “Indices”. Los más importantes son:
- El “Content Index”: indica en que páginas se encuentran cada palabra de texto escrita en el contenido de todos los sitios del “Page Repository”. Funciona igual que el índice alfabético que está al final de los libros: buscás una palabra y el índice te indica en que páginas del libro aparece esa palabra. Las palabras muy comunes tipo “el”, “un”, “a” discriminan tan poco y tendrían una lista de páginas tan grande que son ignoradas por el buscador.
- El “Structure Index”: como su nombre lo indica tiene la información de cómo linkean las páginas entre sí, conociendo para cada página sus links entrantes y salientes. Con esta información se calcula el PageRank.
- Otros índices especiales, como índice de imágenes, archivos pdf, etc.
5) Todo este proceso sucede de manera constante, durante el día y la noche, más allá de que alguien entre a hacer una búsqueda o no. Es decir, es “query-independent”. Supongamos ahora que un usuario ingrese a Google a hacer una búsqueda (lo que sucede más de 300 millones de veces por día). Esa búsqueda entra al “Query Module”, donde se transforman las palabras buscadas en números. Luego éste consulta al “Content Module” para definir cuál es la lista de páginas que tienen contenido relevante de acuerdo a esas palabras buscadas, ordena esa lista según el “content score” (ponderando las páginas que tienen la palabra buscada de manera destacada), trae las páginas relevantes del “Page Repository” y manda todo al "Ranking Module".
6) Finalmente el “Ranking Module” toma la lista de páginas relevantes, busca el PageRank de cada una en el “Structure Index”, calcula el “overall score” de cada página en función del “content score” y el PageRank, re-ordena los resultados según este “overall score” y manda esa lista al usuario. Chin-pum. Todo eso a la velocidad de la luz.
Dediqué 2 horas de un martes a la noche para escribir este post, incluyendo el armado de la imagen. Creo que faltaba una explicación profunda pero clara de cómo funciona un buscador.
Una actualización: me gustó el videito de Matt explicando todo esto de una manera más basica, pero más divertida:
sábado, 28 de junio de 2008
¿Cómo funciona el buscador de Google?
![]()
Suscribirse a:
Comment Feed (RSS)



|