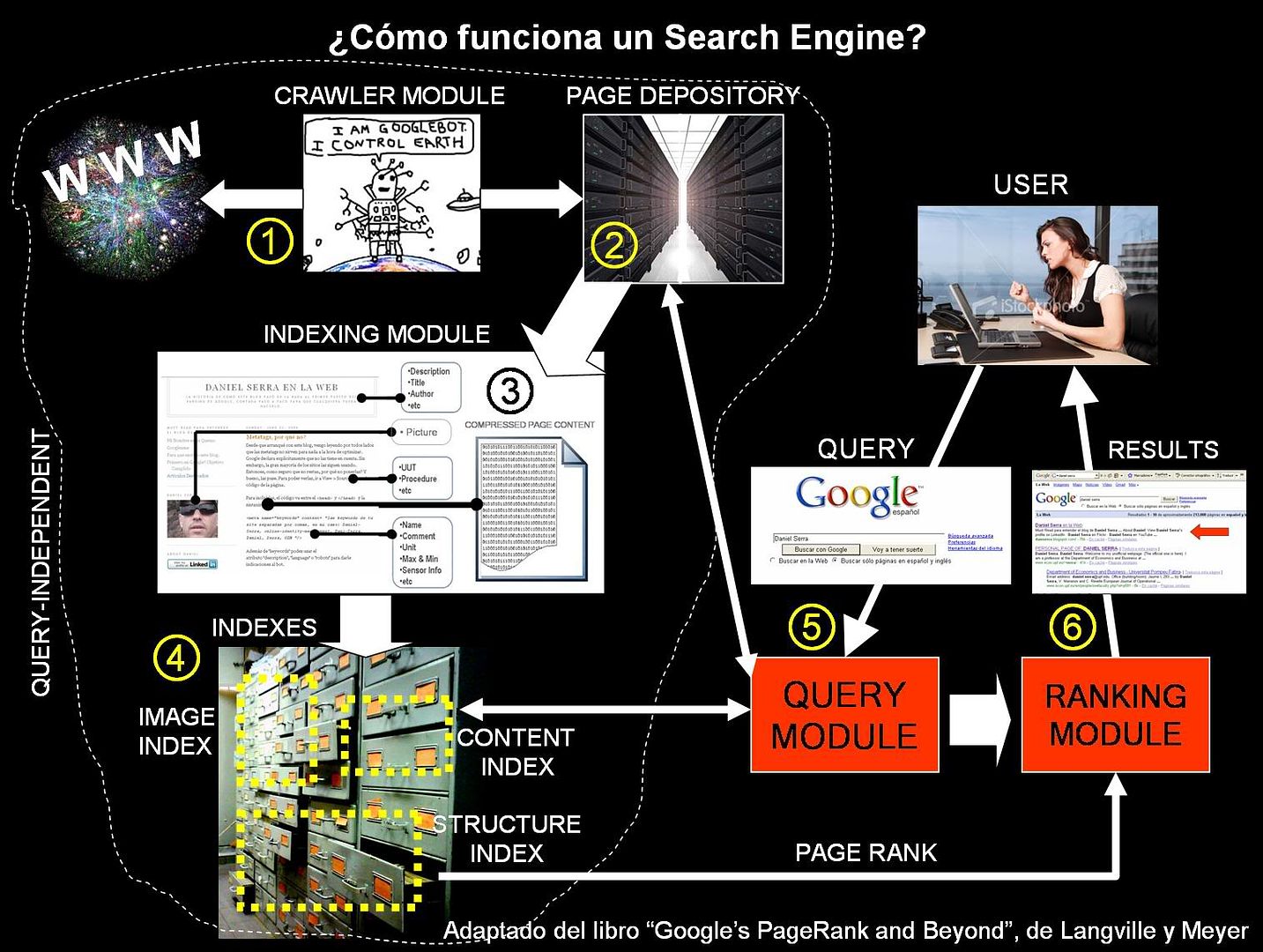
1) Todo empieza con un bot (también llamado crawler, o spider) que se ocupa de recolectar la información que está desparramada por los miles de servers que forman la world wide web. No hay en ningún lado una lista de los sitios web existentes en un determinado momento, las empresas que dan servicio de Search Engine (Google, Yahoo!, etc) deben auto-generarse esa lista. El bot no es ni más ni menos que un programita que visita páginas de internet de manera automática, las copia, las manda al “Page Depository”, luego visita cada uno de los links que tenía esa página y así sucesivamente. De esa manera, recorre la gran mayoría de las páginas de internet existentes y relevantes (Google tenía 8,1 billones a Noviembre del 2004), aunque son muchas las que se le escapan. Ahora, para mantener el “Page Depository” actualizado, las páginas que cambian en forma diaria también deben ser actualizadas diariamente. Para eso existe un bot especial llamado “fresh bot” que visita más frecuentemente los sitios que refrescan su contenido en forma permanente.
2) El “Page Repository” es el caché, o sea, el lugar donde se guarda la última actualización de una determinada página según la copió el bot. Toneladas de información acumulada en discos rígidos. Cuando se hace una búsqueda en Google, al final de cada resultado aparece un link que dice “En caché”. Ahí se puede ver la página que está guardada en el “Page Repository” correspondiente a la última vez que el bot pasó a visitarla. Por supuesto que la página real puede haber cambiado desde ese momento. Acá hay un ejemplo de una página del caché de este blog.
3) El “Indexing module” toma cada página nueva del “Page Repository” y extrae la información más importante, creando una versión comprimida que luego va a ser utilizada en los índices. Esa información incluye: título, descripción, anchor texts, texto en bold o en tamaño mayor, links hacia otras páginas, texto, etc.
4) Con la información extraída en el “Indexing module” se confeccionan los distintos “Indices”. Los más importantes son:
- El “Content Index”: indica en que páginas se encuentran cada palabra de texto escrita en el contenido de todos los sitios del “Page Repository”. Funciona igual que el índice alfabético que está al final de los libros: buscás una palabra y el índice te indica en que páginas del libro aparece esa palabra. Las palabras muy comunes tipo “el”, “un”, “a” discriminan tan poco y tendrían una lista de páginas tan grande que son ignoradas por el buscador.
- El “Structure Index”: como su nombre lo indica tiene la información de cómo linkean las páginas entre sí, conociendo para cada página sus links entrantes y salientes. Con esta información se calcula el PageRank.
- Otros índices especiales, como índice de imágenes, archivos pdf, etc.
5) Todo este proceso sucede de manera constante, durante el día y la noche, más allá de que alguien entre a hacer una búsqueda o no. Es decir, es “query-independent”. Supongamos ahora que un usuario ingrese a Google a hacer una búsqueda (lo que sucede más de 300 millones de veces por día). Esa búsqueda entra al “Query Module”, donde se transforman las palabras buscadas en números. Luego éste consulta al “Content Module” para definir cuál es la lista de páginas que tienen contenido relevante de acuerdo a esas palabras buscadas, ordena esa lista según el “content score” (ponderando las páginas que tienen la palabra buscada de manera destacada), trae las páginas relevantes del “Page Repository” y manda todo al "Ranking Module".
6) Finalmente el “Ranking Module” toma la lista de páginas relevantes, busca el PageRank de cada una en el “Structure Index”, calcula el “overall score” de cada página en función del “content score” y el PageRank, re-ordena los resultados según este “overall score” y manda esa lista al usuario. Chin-pum. Todo eso a la velocidad de la luz.
Dediqué 2 horas de un martes a la noche para escribir este post, incluyendo el armado de la imagen. Creo que faltaba una explicación profunda pero clara de cómo funciona un buscador.
Una actualización: me gustó el videito de Matt explicando todo esto de una manera más basica, pero más divertida:
sábado, 28 de junio de 2008
¿Cómo funciona el buscador de Google?
miércoles, 25 de junio de 2008
La importancia del título del post
Si van a la barra de la izquierda y en el box de "Búsqueda Personalizada en Google" hacen un Search para la keyword Daniel Serra, después de la home, el primer resultado que va a aparecer es el post del 29 de Enero "Daniel Serra en la web, para celulares".
¿Por qué ese post le gana a los otros? Simplemente porque ese post tiene la keyword Daniel Serra en su título (y por lo tanto en la url dado que Blogger utiliza el título del post para generar el permalink). Un buen indicio de la importancia que tiene ese aspecto en la optimización del sitio.
Como dice el gran libro "Google's PageRank and Beyond", el ranking de resultados depende de dos factores: el "content score" y el "popularity score" (voy a profundizar mucho más estos aspectos en el futuro). La combinación de ambos (con ponderaciones que nunca sabremos) determinan un "overall score" que define el orden de los sitios en la página de resultados.
El "popularity score" es intrínseco de la página, y totalmente independiente del query que el usuario esté haciendo en ese momento (en mi caso, Daniel Serra). Se calcula a partir del "popularity score" de las páginas con links entrantes (lo que genera un problema matemático de carácter iterativo) y Google lo mide a través del conocido PageRank. Entonces, el primer concepto (obvio pero fundamental) es que el PageRank es query-independent.
Por otro lado, el "content score", como su nombre lo indica, depende únicamente del contenido (no importándole su popularidad, cantidad de links entrantes, visitas, etc) y pondera al título de la página, su descripción, anchor texts (de los links entrantes), y palabras con font más grande o negritas, por encima del resto del contenido. Como es de suponer, el "content score" de una página es diferente para cada query, y por lo tanto es query-dependent.
Entonces, cuando un usuario hace una búsqueda de una palabra, se calculan los "content scores" de las páginas relacionadas con esa palabra buscada ("relevant pages") generándose un primer ranking. Luego otra aplicación llamada "Ranking Module" va a tomar esa lista y la va a ponderar utilizando el "popularity score" (Page Rank) intrínseco de cada página, calculando así el "overall score", que sirve para ordenar los resultados y dispararlos a nuestro browser en una fracción de segundo.
El post "Daniel Serra en la web, para celulares" no gana por tener mayor popularidad (tiene PR1 como varios otros posts), pero al tener la palabra buscada en el título gana mucho content score lo cual la empuja arriba de todo.
martes, 24 de junio de 2008
Post número 100
 Amigos!! Este es el post número 100 de este blog.
Amigos!! Este es el post número 100 de este blog.
La verdad que pasaron volando.
Un saludo para todos.
Daniel Serra
domingo, 22 de junio de 2008
Metatags, por qué no?
Desde que arranqué con este blog, vengo leyendo por todos lados que las metatags no sirven para nada a la hora de optimizar. Google declara explicitamente que no las tiene en cuenta. Sin embargo, la gran mayoría de los sitios las siguen usando. Entonces, como seguro que no restan, por qué no ponerlas? Y bueno, las puse. Para poder verlas, ir a View > Source y leer el código de la página.
Para incluírlas, el código va entre el <head> y </head> y la sintaxis es:<meta name="keywords" content= "las keywords de tu site separadas por comas, en mi caso: Daniel-Serra, online-identity-management, Dani-Serra, Daniel, Serra, OIM "/>
Además de "keywords" podes usar el atributo "description", "language" o "robots" para darle indicaciones al bot.
domingo, 15 de junio de 2008
El más nerd de los libros


martes, 10 de junio de 2008
El profesor visitó el blog!
Es un verdadero placer anunciar que dos nuevos Daniel Serra visitaron el blog (ambos en el mismo día). Los comentarios que dejaron se pueden leer acá.
El primero es de Valencia, y actualmente vive en Barcelona (el año pasado estuve en Valencia, más o menos en esta época, te hubiera ido a visitar; y de ahí me fuí a correr el encierro a San Fermín). Espero que nos cuente un poco más de su vida. El segundo es nada más ni nada menos que Daniel Serra el profesor de la Universidad de Pompeu Fabra, tan citado en varios posts por la simple razón de que es quien tiene el sitio más fuerte en Google, cabeza a cabeza con este blog. Se está generando un network de Daniel Serras, lo cual me parece simplemente genial. El profesor me dice que además hay otro Daniel Serra profesor, francés, que vive en Montpellier.
El segundo es nada más ni nada menos que Daniel Serra el profesor de la Universidad de Pompeu Fabra, tan citado en varios posts por la simple razón de que es quien tiene el sitio más fuerte en Google, cabeza a cabeza con este blog. Se está generando un network de Daniel Serras, lo cual me parece simplemente genial. El profesor me dice que además hay otro Daniel Serra profesor, francés, que vive en Montpellier.
Justo yo tenía que ser el que vive en el tercer mundo?? : )
Chiste, la verdad que después de haber vivido 4 años en el exterior, volví porque me encanta Buenos Aires.
Esta no es la primer visita de un Daniel Serra al blog, ya nos había visitado el nacido en Mayorca a mediados de febrero, comentado en este post.
Bienvenidos! Muchas gracias por haber escrito comentarios. Me encantaría que sigan participando. Estamos en contacto.
lunes, 9 de junio de 2008
Aplicaciones muy buenas para Yahoo! Search
 Más allá de lo mencionado acerca de la fallida integración de del.icio.us con Yahoo!, hay que destacar lo que están haciendo con las aplicaciones para personalizar resultados.
Más allá de lo mencionado acerca de la fallida integración de del.icio.us con Yahoo!, hay que destacar lo que están haciendo con las aplicaciones para personalizar resultados.
Bajo una iniciativa llamada SearchMonkey, se permite que cualquier desarrollador externo haga aplicaciones para integrar distintos sitios a la página de resultados de Yahoo! (de la misma manera que desarrolladores externos hacen widgets para Facebook por ejemplo), y el resultado se puede ver en el Yahoo! Search Gallery.
Yo sumé la aplicación de LinkedIn, y el search de Daniel Serra me sale así:
O sea, la página de resultados me muestra data tomada de la base de datos de LinkedIn, como foto (que no cargó bien), empresa en que trabajo, cargo, cantidad de conexiones, etc.
Un GRAN paso hacia la personalización de los resultados. Muy Bien Yahoo!
Lo mismo puede hacerse para last.fm, StumbleUpon, Wikipedia, Facebook, etc.
sábado, 7 de junio de 2008
Integración fallida
Hace varios meses, TechCrunch ya anunciaba la integración de del.icio.us con Yahoo! Search en una misma página de resultados. La combinación me pareció explosiva, Yahoo! podría incorporar a la página de resultados generada por el bot, algo que Google no puede: los sitios que los mismos usuarios están bookmarkeando y tageando como interesantes. Acá va un ejemplo de lo que sería la búsqueda de "Java" (imágen tomada de la nota de TechCrunch):
Meses después de esa nota, la integración todavía no se ve. Hice decenas de búsquedas en Yahoo! Search y no pude encontrar ninguna que muestre cuanta gente bookmarkeó cada resultado en del.icio.us. Ni siquiera la búsqueda de Java tiene los resultados mostrados en la imágen de arriba.
Una lástima...una buena idea que no se pudo ejecutar. Por ahora...
lunes, 2 de junio de 2008
del.icio.us tiene competencia




